Datenbanktheorie |
|
letzte Aktualisierung / last update: 21.01.2023
|
Datenbank-Management-Ausb.
|
Datenbank-Management-Ausb.
|
SQL Server 6.5 |
SQL Server 6.5
|
Data Management Training |
Design Management |






|
1. Datenbank-Managementsysteme
|
|
1.1 Aufgaben und Bedeutung
|
|
1.2 Technologie
|
|
2. Konzeptioneller Datenbankentwurf
|
|
3. Ein Anwendungsbeispiel
|
|
4. Relationaler Datenbankentwurf - Normalformenlehre
|
|
4.1 Erste und zweite Normalform
|
|
4.2 Dritte Normalform
|
|
4.3 Weitere Normalformen
|
|
4.4 Integritätsbedingungen
|
|
5. Entity Relationship Modell
|
|
5.1 Entstehung und Stellenwert
|
|
5.2 Basis-Elemente des ERM
|
|
5.3 Erweiterungen des elementaren ERM
|
|
5.4 Notationsvarianten
|
|
5.5 Diskussion der Modellierungsreichhaltigkeit
|
|
6. Umsetzung eines ER-Modells
|
|
7. Modellierung von Operationen und Funktionen
|
|
Literatur
|
1. Datenbank-Managementsysteme
- Aufgaben und Bedeutung
- Technologie
-
1.1 Aufgaben und Bedeutung
Die wirtschaftliche Bedeutung von Datenbankmanagement-Systemen und darauf aufbauenden datenbankgestützten Anwendungen hat wesentlich den heutigen Stellenwert der Informatik mit begründet. Aus dem Rückblick scheint die Entwicklung des Begriffs und Teilfaches Datenbanksysteme so zwangsläufig, daß man sich nur schwer gedanklich in die historische Situation zurückversetzen kann, in der sich das Konzept als Ergebnis einer intensiven und kontroversen Diskussion herausgebildet hat.
In der "Steinzeit" der Datenverarbeitung war jedes Programm selbst für das Schreiben und Lesen derjenigen Daten, die den Programmlauf überdauern sollten, vollständig zuständig. Konsequenz: Der weitaus größte Anteil der Programmierbefehle beschäftigte sich mit dem Ansteuern der Speicher-Hardware und war demzufolge von dieser Hardware auch abhängig. Ein Fortschritt in der Speichertechnologie bedeutete ein Umschreiben der Programme.
Das "Mittelalter" ist gekennzeichnet durch eine Dateiverwaltung, die den Programmen geeignete Zugriffsmethoden zur Verfügung stellt und diese somit unabhängig von der Hardware macht. Aber immer noch verwaltet jedes Programm seine Daten und dies hat bei der Vielzahl von Programmen einen grundlegenden Nachteil: identische Daten finden sich in vielen verschiedenen Dateien wieder und sind kaum zuverlässig konsistent zu halten. Abhilfe schafft nur die gemeinsame Nutzung einer Datei durch viele Programme mit wiederum einem höchst unerwünscheten Nebeneffekt: Die Programme sind insofern voneinander abhängig geworden, als eine Änderung der Dateistruktur, die für ein Programm notwendig wird, die Anpassung aller Programme verlangt, die diese Datei ebenfalls benutzen.
Der "Neuzeit" wollen wir das Datenbank-Konzept zuschreiben, mit dem wir das Ziel der Datenunabhängigkeit anstreben: Wir zentralisieren die Verwaltung der Daten und heben die strikte Zuordung einzelner Datenelemente zu einzelnen Programmen auf. Ein Programm "`weiß"' nicht, wie die Daten tatsächlich gespeichert sind, sondern fordert die Daten in der benötigten Zusammenstellung und im richtigen Format vom Datenbankmanagement-System an. Eine strukturelle Änderung des Datenbestandes (z.B. durch Aufnahme neuer Datenelemente) bleibt den Programmen verborgen: Die Datenbank beliefert sie mit einer Sicht auf den Datenbestand, der vollständig der alten unveränderten Situation entspricht.
Die Zentralisierung der Daten vergrößert entscheidend den Schaden, der durch Verfälschung oder Verlust der Daten droht. Gleichzeitig schafft sie eine Situation, in der die Wahrscheinlichkeit für einen Schadensfall beliebig minimiert werden kann: durch zentrale Maßnahmen der Qualitätssicherung (Datenintegrität) und der Datensicherung (Recovery).
Im Hinblick auf das Thema dieses Beitrags zu Datenbank-Entwurfsmethoden erscheint verzichtbar, auf andere wichtige Ziele und Eigenschaften von (DBMS) einzugehen, z.B. den der gleichzeitigen Nutzung durch mehrere Programme bzw. Personen.1.2 Technologie
Die Szene der Datenbanknutzung wurde in einer ersten und keineswegs kurzen Zeit von sogenannten hierarchischen DBMS bzw. von deren Erweiterungen hin zu Systemen mit einer Netzwerk-Architektur beherrscht. Daß man mit diesen Datenbank-Architekturen vom Ziel der Datenunabhängigkeit recht weit entfernt blieb, beeindruckte die Praktiker weniger als die Vorteile auf der Performance-Seite. Die Theorie relationaler Datenbanken wurde dagegen lange Zeit als Spielwiese der Hochschulforschung abgetan und hat erst nach etwa zehn Jahren Praxisrelevanz erlangt. Sie gilt heute --- zumindest was neue Anwendungen betrifft --- als Standard-Technologie.
1993 erreichten die Marktumsätze relationaler Datenbanksysteme die der nichtrelationalen. Allerdings befanden sich zum gleichen Zeitpunkt 80 % der Unternehmensdaten noch in nicht-relationalen Systemen.
Mit dem Vordringen der Datenbank-Technik in die vielfältigen Bereiche der Praxis stellte es sich überraschenderweise (!) heraus, daß auch die relationalen Systeme keineswegs so anwendungsunabhängig sind, wie die Hochschulwelt postuliert hatte. Stattdessen stecken in dem gewählten Ansatz implizite Annahmen über die abzubildende Datenwelt, die keineswegs von jeder Anwendung erfüllt werden. Non-Standard-Datenbanken für Non-Standard-Anwendungen heißt die Antwort. Schlagwörter für diese Datenmodelle der 3. Generation sind aktive, deduktive und insbesondere objektorientierte Datenbanken.
2. Konzeptioneller DatenbankentwurfDBMS als Werkzeuge. Wer seine Daten mit einem verfügbaren Datenbankmanagement-System verwalten will, hat sich mit dieser Software zunächst nicht eine Lösung, sondern ein Werkzeug eingekauft: Vergleichbar einer Thesaurus-Software, die dem Nutzer die Arbeit der eigentlichen Entwicklung des Thesaurus nicht abnehmen kann. Eine sinnvoll aufgebaute Datenbank muß in gewisser Weise die Struktur des Weltausschnittes widerspiegeln, dessen Daten zu speichern und zu verwenden sind: Diese Struktur ist nicht einfach gegeben: sie muß z.T. entdeckt und z.T. konstruktiv entworfen werden, und zwar beim konzeptionellen Datenbankentwurf.
Schichtenmodell. Wie alle komplexe Systeme versteht man und den Umgang mit ihnen besser, wenn man sie auf verschiedenen Abstraktionsniveaus (Schichten) betrachtet und beschreibt:
Zugriffsmethoden, die auf den physikalischen Speicherstrukturen arbeiten,
setzen wir als Schnittstelle zum DBMS voraus. Damit ist Geräte-Unabhängigkeit gegeben.
Die interne Sicht schafft darauf aufbauend Unabhängigkeit von Zugriffspfaden und Speicherstrukturen. Aus interner Sicht ist der Speicher homogen und unbeschränkt. Begriffe zur Realisierung der internen Sicht sind Dateien, Sätze, Felder, Indexing-Techniken, Datenkompression, symbolische Pointer.
Die konzeptionelle Sicht beschreibt umfassend und integrierend die Struktur der Datenbank. Soweit diese Struktur frei von vordefinierten Zugriffspfaden ist, schafft diese Ebene Daten-Unabhängigkeit. Im relationalen Modell besteht die konzeptionelle Sicht aus einer Menge von Relationen (Tabellen), die Objekte und Objektbeziehungen uniform repräsentieren. Andere Ansätze wie das Entity Relationship Modell bieten hier ein "Mehr" an Semantik.
Die externen Sichten definieren für die einzelnen Anwendungen individuelle Sichten auf die Datenbank: Jede Anwendung soll den Eindruck haben, als sei die Datenbank einzig und ausschließlich für ihre Zwecke definiert.
Anwendungsbereiche. Dem konzeptionellen Datenbankentwurf geht die Einschätzung voraus, daß es sich im vorliegenden Fall überhaupt um ein Informationsproblem handelt, für das geeignet sind. Es wird sich also um einen Anwendungsfall mit etwa der folgenden Charakterisierung handeln:
- In der abzubildenden Welt lassen sich einzelne Datenelemente
mit festumrissener Interpretation abgrenzen. Wenn prinzipiell
die Organisation der benötigten Daten in einer Tabellenform
sinnvoll erscheint, ist diese Voraussetzung erfüllt.
- Die Vorteile heutiger lassen sich gerade dann gut nutzen, wenn
eine gewisse strukturelle Komplexität gegeben ist, wenn also
dieselben Daten --- unter verschiedenen Perspektiven betrachtet
--- unterschiedlich zusammengestellt werden können. Andererseits
wird die Eignung konventioneller DBMS'e fraglich , wenn das, was aus Anwendungssicht ein zusammengehöriges Ganzes ist, sich --- wiederum in Tabellen gedacht --- auf zuviele Tabellen verteilt.
- Zusammenfassend kann man sagen, daß es ein vergleichsweise überschaubares Schema gibt, in das sich beliebig viele Daten einpassen und speichern lassen.
Haben beispielsweise die zu speichernden Daten in erster Linie Textcharakter (z.B. wie dieser Beitrag hier) so wäre ein Textretrievalsystem und nicht ein das System der Wahl. Sofern man sich dabei auf den ISO-Standard SGML abstützt, entspricht die Dokumentenanalyse und die Entwicklung einer Document Type Definition (DTD) genau dem, was auf der Datenbankseite konzeptioneller Datenbankentwurf heißt.
Miniwelt. Es mag beim Lesen in einem Lehrbuch schwer nachzuvollziehen sein, aber eine der tatsächlich besonders wichtigen und auch schwierigen Aufgaben beim konzeptionellen Datenbankentwurf ist die präzise Bestimmung des abzubildenden Weltausschnittes, der sogenannten Miniwelt. Zu klären ist also, welche der potentiell relevanten Daten und strukturellen Zusammenhänge tatsächlich in der Datenbank gebraucht werden. Es bedarf oft vieler Diskussionen mit verschiedenen Anwendern, um hier zu einer klar begründeten und allgemein akzeptierten Entscheidung zu kommen.
Stellenwert der Anwendungen. Wenngleich eine wesentliche Motivation für das Entstehen von DBMS'en gerade die Unabhängigkeit der Datenbank von den sie nutzenden Anwendungen ist, so ist aber andererseits ein richtiger Datenbankentwurf nur vor dem Hintergrund einer klaren Vorstellung dessen möglich, was man mit den zu speichernden Daten anstellen will: welches also die Anwendungen sind. Ein gleichartiges Spannungsfeld zwischen Anwendungsabhängigkeit und -unabhängigkeit gilt auch für den Einsatz von SGML, wenn es um die Verwaltung von Textdaten geht.
Ansätze der Datenmodellierung. Für den Datenbankentwurf wurden zunächst --- in guter Informatik-Tradition --- formale Modelle entwickelt, die offensichtlich eine gute Grundlage für ein tiefes Verständnis des Problembereichs liefern und sich auch im praktischen Einsatz bewährt haben: Nach den elementaren Anfängen (File-Modelle) die klassischen Datenmodelle (Hierarchisch, Netzwerk, Relational). Allerdings haben Anwender nachvollziehbarerweise große Schwierigkeiten, die Ergebnisse des Datenbankentwurfs kritisch zu überprüfen oder gar selbst diese Modelle zu erstellen.
Als Alternative bieten sich Methoden der semantischen Datenmodellierung an. Hierbei geht man von der Sicht aus, die der Benutzer auf die darzustellende Welt hat, also von der Bedeutung der Daten und der dadurch repräsentierten Eigenschaften der Welt. Dieser Ansatz ist dem Nutzer sehr viel näher, sowohl in seiner Rolle als Gesprächspartner (und evtl. Auftragsgebers) des Datenbank-Entwicklers als auch eventuell selbst als Entwerfer der Datenbank.
Zunehmende Bedeutung erlangen Modelle für Non-Standard-Anwendungen.3. Ein Anwendungsbeispiel
Als ein durchgängiges Anwendungsbeispiel für das Folgende betrachten wir einen fiktiven Weltauschnitt vom Hildeshofer Zentrum für berufliche Weiterbildung.
Hildeshofer Zentrum für berufliche Weiterbildung
Das Hildeshofer Zentrum für berufliche Weiterbildung hat in den letzten Jahren eine bemerkenswerte Entwicklung durchgemacht und kann inzwischen mit einem breiten Angebot an Fortbildungsveranstaltungen aufwarten. Das ist für die MitarbeiterInnen erfreulich, bringt aber auch Probleme mit sich, da das halbjährliche Drucken der Kataloge, das Führen der Teilnehmerlisten etc. auf der Basis manuell geführter Listen und Kursankündigungen doch recht mühsam geworden ist. Denn außer einer kleinen Kunden-Adressdatenbank gibt es bisher keine technische Unterstützung...
Was wir damit zu tun haben, fragen Sie? Nun, uns ist es gelungen, einen tollen Job an Land zu ziehen. Wir sollen die Verwaltungsangestellte unterstützen, der die Arbeit mittlerweile über den Kopf wächst. Wir sollen für Kursangebot und Kursanmeldungen und -teilnahme einen Datenbankentwurf liefern und später daraus eine Anwendung "stricken".
Nun Katrin Kleitz, eben jene Verwaltungsangestellte, hat uns mittlerweile folgendes klargemacht:
1. Das Kursangebot ist in Bereiche gegliedert, die auch den Kursprospekt strukturieren. Jeder Bereich hat einen eindeutigen Kennbuchstaben, eine Bezeichnung sowie einen Kurz- und einen
Langtext zur näheren Erläuterung.
Der Bereich "E" beispielsweise umfaßt alle Kurse zum Thema "EDV-Grundwissen". Im Kursprospekt findet sich im einführenden Teil eine ausführliche Erläuterung dazu. Eine kurze Erläuterung leitet dagegen im Hauptteil des Prospektes die nachfolgenden Kursankündigungen ein.
2. Auf den letzten Seiten des Kursprospektes stellen sich die DozentInnen mit ihrem Namen, ihrer Telefonnummer und einem kurzen Statement über ihren Kompetenzbereich vor. Das verwaltungsintern verwendete 2-stellige Namenskürzel erscheint nicht ausgedruckt.
3. Jeder Kurs hat zusätzlich zur Kursbezeichnung eine eindeutige Kursnummer. Weiterhin gehören zu jedem Kurs eine Beschreibung der Kurs-Inhalte, Halbjahr, Kursgebühr und die verantwortlichen DozentInnen. Die Kurse erscheinen im Prospekt unter genau einer Bereichsüberschrift.
Der Einfachkeit wegen unterschlagen wir weitere Einzelheiten wie Beschreibung der Zielgruppen, minimale und maximale Teilnehmeranzahl, Kursdauer, Anmeldeschluß, regelmäßiger Termin u.a.
4. Die Kursteilnehmer müssen sich anmelden und bekommen nach Eingang der Zahlung ihre Anmeldungsbestätigung unter Angabe des Zahlungsdatums schriftlich an ihre Adresse zugeschickt.
Da bereits eine Adressdatenbank besteht und man sich über die Zahlungsverwaltung noch nicht ganz im klaren ist, sollen diese Aspekte (Adresse, Verwaltung des Kunden-Kontos) zunächst ausgeklammert bleiben. Wichtig ist allerdings, daß die bisher verwendete Kundennummer (eine fortlaufende Nummer in der Adressdatenbank) auch in der neuen Datenbank ihren Platz hat.
5. Am Ende eines Kurses werden den teilnehmenden Personen Teilnahmebestätigungen ausgehändigt. Die Kursleiter übermitteln der Verwaltung für jede Kursteilnahme eine Text-Nummer, die für das Zertifikat in einen freundlichen Text über den Teilnahme-Erfolg umgesetzt wird.
Frau Sabine Sandmann-Süllenberger hat im zweiten Halbjahr 1996 an dem Kurs "Englisch für das Büro" teilgenommen. Ihr Abschlußertifikat liest sich etwa wie folgt:
Das Hildeshofer Zentrum für berufliche Weiterbildung bestätigt Frau Sabine Sandmann-Süllenberger die erfolgreiche Teilnahme am Kurs "Englisch für das Büro" (96/2). Die Teilnehmerin hat sich an den schriftlichen und mündlichen Übungen mit ausdauerndem Fleiß und recht gutem Erfolg beteiligt.
Die zu entwickelnde Datenbank wird die Verwaltung in verschiedener Hinsicht
unterstützen müssen: Beim Drucken der Teilnehmerlisten und Teilnahmebestätigungen, bei der Aktualisierung der Kursdaten und -beschreibungen, bei Auskünften am Telefon, bei Druck und Versand des Prospektes. Beispielsweise wird Kunden, die in den letzen 3 Jahren an mindestens 2 Kursen teilgenommen haben, halbjährlich unaufgefordert der jeweils neue Prospekt zugeschickt. Nach Vervollständigung der Datenbank soll auch die Anmeldung mit Erfassung der Personaldaten, Verwaltung der Einzahlungen und das Mahnwesen unterstützt werden.4. Relationaler Datenbankentwurf: Normalformenlehre
- Erste und zweite Normalform
- Dritte Normalform
- Weitere Normalformen
- Integritätsbedingungen
4.1 Erste und zweite Normalform
Relationale DBMS. Die Normalformenlehre ist eine formale Entwurfsmethode für relationale Datenbanken. Für die Zwecke dieses Beitrags mag es einführend ausreichen, relationale Datenbankmanagementsysteme (RDBMS) als Programme zu charakterisieren, die Daten in Form von Tabellen verwalten. Identische Tabellenzeilen gibt es in solchen Tabellen allerdings nicht. Datenbankentwurf heißt nun, die benötigten Tabellen im einzelnen festzulegen. Zur späteren Nutzung stellen RDBMS ein klar umrissenes (und theoretisch gut begründetes) Inventar an Operationen zur Verfügung, mit der sich neue Tabellen (nämlich solche mit dem Ergebnis einer Anfrage) aus den vorhandenen Tabellen ableiten lassen. Der Name "relationale" Datenbanken kommt daher, daß die Tabellen nichts anderes sind als die Darstellungsform dessen, was die Mathematik Relationen nennt, die dann mit formalen Sprachen auf der Basis des Relationenkalküls oder der Relationenalgebra manipuliert und abgefragt werden. Die Gründe für den Erfolg des relationalen Datenbank-Konzeptes sind ein überzeugender Beleg für die Behauptung, derzufolge "nichts so praktisch ist wie eine gute Theorie".
"Richtige" Tabellen. Nun stellt es sich schnell heraus, daß dieselbe Datenwelt durchaus unterschiedlich in Tabellen organisiert werden kann und daß diese unterschiedlichen Ent-wür-fe keineswegs gleichwertig sein müssen. Vielmehr können bei ungeschickter Tabellendefinition sehr unerwünschte Fälle auftreten, die man als Anomalien bezeichnet und denen man man unbedingt ausweichen will. Die Lösung für dieses Problem liefert die von Codd (und im weiteren Ausbau auch von anderen) entwickelte Normalformenlehre, die diejenigen Regeln formalisiert, die die intuitiven Entscheidungen umsichtiger Datenbankentwickler bereits vorher bestimmt haben. Die verschiedenen "unerwünschten Effekte" lassen sich in Lösch-, Einfüge- und Änderungs-Anomalien (siehe Abb. 4.1) systematisieren:
Lösch-Anomalie Sollte es nur einen Eintrag für die Dozentin Anna Huller geben, so wird mit dem Kurs 144 unabsichtlich auch diese Dozentin aus der Datenbank gelöscht.
Einfüge-Anomalie Soll die neue Dozentin Tina Wolf eingetragen werden, noch bevor ein Kurs bekannt ist, den sie zu halten hat, so ist dies hier nicht möglich. Der Ausweg einer unvollständigen Tabellenzeile führt nicht weiter, weil (wie in Zusammenhang mit Definition 4 diskutiert wird) die Datenbank die Zeile ohne den Schlüssel Kurs_Nr nicht akzeptiert.
Änderungs-Anomalie Das Ändern der Telefonnummer kann zu Inkonsistenzen führen, wenn nach der Änderung dieselbe Person mit unterschiedlichen Telefonnummern in der Datenbank steht.
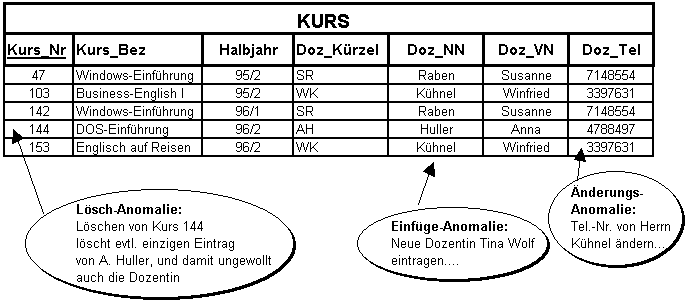
Abbildung 4.1: Lösch-, Einfüge- und Änderungs-Anomalien am Beispiel.Universal Relation und Normalformenlehre. Zumindest vom gedanklichen Ansatz her beginnt die Normalformenlehre mit einer einzigen umfassenden Tabelle, der Universal Relation. Diese Tabelle soll später schrittweise so in Teiltabellen zerlegt werden, daß keine Information und keine Datenabhängigkeiten verlorengehen (siehe Abb. 4.2), keine Anomalien mehr auftreten können und die Zahl der Tabellen möglichst klein gehalten wird.
Um die Universal Relation zu konstruieren, müssen alle Datenelemente zusammengestellt werden, die in die Datenbank aufgenommen werden sollen. Solche Datenelemente nennen wir Attribute einer Relation: sie werden beschrieben durch eine Definition und durch Angabe eines Datentyps bzw. Wertebereichs. Gängige Datentypen sind Zeichenstrings fester oder variabler Länge, Fest- oder Gleitkommazahlen (Integer, Floating Point), Datumsangaben, Geldbeträge. Eine häufige Form sind auch enumerative Datentypen, bei der man die einzelnen Werte aufzählt: beispielsweise als {rot, grün, blau}.
Bei unserem Hildeshofer Beispiel besteht die Universal Relation aus folgenden Attributen vom TypInteger: Kursnummer, Kundennummer, Textbaustein-Nummer.
Geldbetrag: Kursgebühr.
Datum: Zahlungseingang.
Zeichenstring variabler Länge: Bereich-Bezeichnung, Bereich-Kurztext, Bereich-Langtext, Dozent-Vorname, Dozent-Nachname, Dozent-Telefonnummer, Kompetenzbereich, Kursbezeichnung, Kurs-Inhalte, Kunde-Vorname, Kunde-Nachname, Textbaustein.
Zeichenstring fester Länge: Bereich-Kennbuchstabe, Dozent-Namenskürzel, Halbjahr. Aufzählungstyp: Kundengeschlecht {m, f}.
Eine reale Datenbankentwicklung erfordert, die Wertebereiche der Attribute noch weitergehend zu spezifizieren (Beispiele: Telefonnummer, Halbjahr) und den Inhalt der Attribute genauer zu dokumentieren. Darauf wird an dieser Stelle nicht weiter eingegangen. Gegebenenfalls siehe dazu auch Abb. 4.7.
Im folgenden werden z.T. informelle und selbsterklärende Abkürzungen als Attributnamen verwendet.

Abbildung 4.2: Verlustfreiheit von Tabellenzerlegungen.
Nicht jede Tabellenzerlegung ist verlustfrei: Aus den Teiltabellen K und B läßt sich die Ursprungstabelle KURS nicht mehr rekonstruieren. Der innere Zusammenhang der Daten wurde zerrissen.Erste Normalform. Die Universal Relation wird in der sogenannten ersten Normalform vorausgesetzt. Dazu wird gefordert, daß alle Attributwerte atomaren Charakter haben, also aus Sicht des Datenbank keine interne Struktur besitzen: wie z.B. ein Nachname, eine Kursnummer oder ein Kursgebühr. Tabellenzeilen, die sogenannte Mehrwertattribute enthalten, müssen so vervielfacht werden, daß jede Zeile in jedem Attribut nur einen einzigen Attributwert speichert (siehe Abb. 4.3). Relationen in der ersten Normalform sind also "flache Tabellen" ohne jede "Schachtelung".
Hier wird schon deutlich, daß Texte eigentlich nicht so recht ins System passen. Nehmen wir beispielsweise den Kurs_Inhalt, so handelt es sich kaum tatsächlich um einen atomaren Attributwert, denn er besteht aus einzelnen Wörtern. Im Kontext relationaler Datenbanken fassen wir jedoch zweckmäßigerweise Kurs_Inhalt als einen Zeichenstring ohne interne Struktur auf.

Abbildung 4.3: Mehrwertige Attribute können immer ohne Informationsverlust beseitigt werden.Funktionale Abhängigkeiten. Um nun von der ersten zu den weiteren Normalformen zu kommen, müssen wir das grundlegende Konzept von der funktionalen Abhängigkeit verstanden haben:
Definition 1 Ein Attribut B ist von einer Attributmenge A1 ... An funktional abhängig, wenn es keine Tabellenzeilen (Datensätze) mit verschiedenen Werten für B, aber denselben Attributwertkombinationen a1 ... an geben kann.
Beispiel(1): Das Attribut Textbaustein_Nummer ist funktional abhängig von Kurs_Nr, Kundennummer, weil es ausgeschlossen ist, daß für eine Kursteilnahme verschiedene Textbausteine angegeben werden. Beispiel(2): Das Attribut Ber_Bezeichnung ist funktional abhängig von Ber_KB , weil es ausgeschlossen ist, daß es für einen Bereichs-Kennbuchstaben verschiedene Bereichsbezeichnungen geben kann. Umgekehrt gilt dies auch, so daß zusätzlich Ber_KB funktional abhängig ist von Ber_Bezeichnung (siehe Abb. 4.4).
Im weiteren brauchen wir eine Verschärfung des Konzeptes der funktionalen Abhängigkeit: Wir sagen
Definition 2 Ein Attribut B ist von einer Attributmenge A1 ... An voll funktional abhängig, wenn es funktional abhängig ist und die Attributmenge A1 ... An gewissermaßen minimal definiert ist: Bei Weglassen irgendeines der A¡ darf die Abhängigkeit nicht mehr gelten.
Konsequenz: Ist B von genau einem Attribut A funktional abhängig, dann gilt notwendigerweise auch die volle Abhängigkeit.
In Abb. 4.4 sind all diejenigen voll funktionalen Abhängigkeiten graphisch dargestellt, die sich nicht transitiv ableiten lassen: Wenn nämlich Ber_Kurztext abhängig ist von Ber_KB und Ber_KB abhängig ist von Kurs_Nr, dann gilt nach dem Gesetz der Transitivität: Ber_Kurztext ist abhängig von Kurs_Nr. Solche erschließbaren Abhängigkeiten sind der Übersicht halber nicht eingezeichnet.
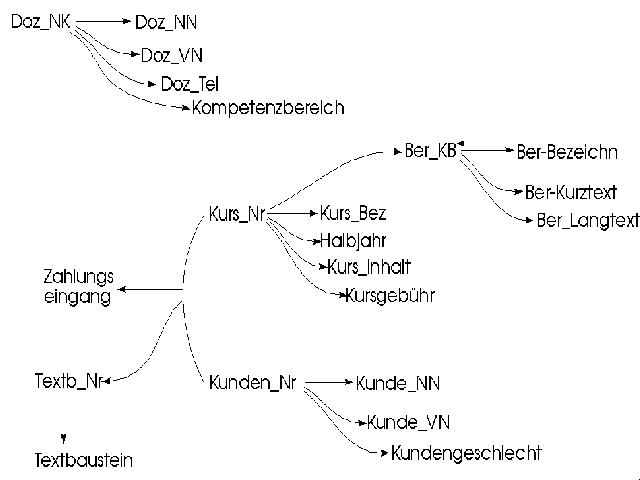
Abbildung 4.4: Voll funktionale Abhängigkeiten in der exemplarischen Miniwelt.
Zweite Normalform. Die zweite Normalform bricht nun die Universal Relation in sinnvolle Teiltabellen auf. Um diesen Prozess formulieren zu können, benötigen wir ein weiteres zentrales Konzept der relationalen Datenbank-Theorie: Die Schlüsseleigenschaft von Attributen für eine Relation.
Definition 3 Eine Kombination von Attributen A1, ... An heißt Schlüsselkandidat und besitzt die Schlüsseleigenschaft für eine Relation, wenn es keine zwei Tabellenzeilen geben kann mit einer identischen Wertebelegung a1,...an. Die Attribute A1, ... An identifizieren also eine Tabellenzeile. Die Attributkombination muß überdies minimal gewählt sein: Bei Weglassen eines der Attribute Ai darf die identifizierende Eigenschaft nicht mehr gelten.
Beispiel Betrachten wir die zwei Tabellen:
KURS ( Kurs_Nr, Kurs_Bez, Halbjahr, Kurs_Inhalt, Kursgebühr)
TEILNAHME ( Kurs_Nr, Kunden_Nr, Zahlungseingang)
dann identifizieren die unterstrichenen Attribute jeweils eine Tabellenzeile. Wenn ich z.B. mit dem Schlüssel Kurs_Nr in der Tabelle KURS suche, kann ich immer nur eine Tabellenzeile als Antwort bekommen, denn Kurs_Nr identifiziert jeweils eine Zeile. Es kann keine zwei verschiedenen Zeilen mit derselben Kursnummer geben!
Es ist für das weitere zweckmäßig, eine einfache Definitionen nachzuschieben:
Definition 4 Gibt es in einer Relation mehrere Schlüsselkandidaten so wird einer davon zum Schlüssel der Relation bestimmt. Die Angabe des Schlüssels ist für jede Relation wichtig und obligatorisch.
Damit haben wir den die schlimmsten Zumutungen durch Definitionen überstanden und können wir die zweite Normalform relativ einfach festlegen:
Definition 5 Eine Relation befindet sich in der zweiten Normalform, wenn sie sich in der ersten Normalform befindet und wenn kein Attribut in der Relation, das nicht zum Schlüssel gehört, nur von einem Teil des Schlüssels voll funktional abhängt. Konsequenz: besteht der Schlüssel einer Relation in erster Normalform nur aus einem Attribut, so befindet sie sich automatisch auch bereits in zweiter Normalform.
Beispiel Aus der Universal Relation werden in unserem Beispiel folgende Relationen in zweiter Normalform abgeleitet:
DOZENT ( Doz_NK, Doz_NN, Doz_VN, Doz_Tel, Kompetenzbereich)
KURS ( Kurs_Nr, Ber_KB, Ber_Bezeichn, Ber_Kurztext, Ber_Langtext, Kurs_Bez, Halbjahr, Kurs_Inhalt, Kursgebühr)
LEITUNG ( Doz_NK, Kurs_Nr)
KUNDE ( Kunden_Nr, Kunde_NN, Kunde_VN, Kundengeschlecht)
TEILNAHME ( Kurs_Nr, Kunden_Nr, Zahlungseingang, Textb_Nr, Textbaustein)
Beim Lesen ist zu beachten, daß jede Tabelle (Relation) einen Namen zugeordnet bekommt und daß in der Liste seiner Attribute der Schlüssel durch Unterstreichung und Fettschrift gekennzeichnet ist.
Als Beispiel für eine Relation, die sich nicht in zweiter Normalform befindet, mag folgende Tabelle dienen:
KURS_TEILNAHME ( Kurs_Nr, Kunden_Nr, Ber_KB, Zahlungseingang)
Hier ist das Attribut Ber_KB nicht vom gesamten Schlüssel, sondern nur von einem Teil, dem Attribut Kurs_Nr, voll funktional abhängig.
4.2 Dritte Normalform
Bei genauer Analyse fällt auf, daß die zweite Normalform noch nicht gegen Anomalien gefeit ist.
Ein neuer Bereich kann nur eingetragen werden, wenn es schon einen Kurs dafür gibt (Einfüge-Anomalie in KURS). Soll z.B. der Textbaustein Nr. 4 für das mäßig gute Abschneiden etwas freundlicher formuliert werden, treten Inkonsistenzen auf, wenn er nicht korrekt überall dort geändert wird, wo Textbaustein Nr. 4 verwendet wird (Einfüge-Anomalie in TEILNAHME. Gibt es in einem Bereich nur einen Kurs und dieser wird gelöscht, so ist auch dieser Bereich in der Datenbank nicht mehr gespeichert (Lösch-Anomalie in KURS).
Der Grund liegt darin, daß manche Attribute nur indirekt (transitiv) vom Schlüssel abhängig sind. Diese Fälle soll die dritte Normalform beseitigen.
Definition 6 Eine Relation befindet sich in dritter Normalform, wenn sie der zweiten Normalform genügt und kein Attribut transitiv von einem Schlüsselkandidaten abhängig ist.
Als Beispiel dient uns die Relation KURS, in der das Attribut Ber_Kurztext von Ber_KB und dieses wiederum vom Schlüssel Kurs_Nr abhängig ist.
Abbildung 4.5 zeigt den nunmehr endgültigen Datenbankentwurf für das Hildeshofer Zentrum für berufliche Weiterbildung in dritter Normalform.
DOZENT ( Doz_NK, Doz_NN, Doz_VN, Doz_Tel, Kompetenzbereich)
BEREICH ( Ber_KB, Ber_Bezeichn, Ber_Kurztext, Ber_Langtext)
KURS ( Kurs_Nr, Ber_KB, Kurs_Bez, Halbjahr, Kurs_Inhalt, Kursgebühr)
LEITUNG ( Doz_NK, Kurs_Nr)
KUNDE ( Kunden_Nr, Kunde_NN, Kunde_VN, Kundengeschlecht)
TEILNAHME ( Kurs_Nr, Kunden_Nr, Zahlungseingang, Textb_Nr)
URTEIL_TEXTE ( Textb_Nr, Textbaustein)
Abbildung 4.5: Datenbankentwurf in dritter Normalform.
Wir sehen hier deutlicher noch als bei den Relationen der zweiten Normalform ein Strukturprinzip relationaler Datenbanken: Zwischen den einzelnen Tabellen werden Bezüge dadurch hergestellt, daß Attribute, die Schlüssel einer Relation sind, auch in anderen Tabellen verwendet werden. Textb_Nr ist Schlüssel der Relation URTEIL_TEXTE und tritt darüber hinaus in der Relation TEILNAHME auf. Dies führt und zu einem neuen Begriff:
Definition 7 Ein Attribut heißt Fremdschlüssel in einer Relation R_1, wenn es eine Relation R_2 gibt, in der es Schlüssel ist.
Definition 8 Referenzielle Integrität liegt in einer Datenbank vor, wenn jedem Wert, der unter einem Fremdschlüssel eingetragen wird, auch tatsächlich ein identischer Eintrag in der Relation entspricht, in der das Attribut Schlüssel ist. Beispiel: Die referenzelle Integrität ist verletzt, wenn in der Tabelle TEILNAHME eine Textbaustein-Nummer verwendet wird, die in der Tabelle URTEIL_TEXTE gar nicht auftritt.
Das Ziel des "Praktiker" ist in der Regel ein Datenbankentwurf in der dritten Normalform, die damit eine Art Gütesiegel für einen "richtigen" Datenbankentwurf darstellt. Zwar mag es durchaus gute Gründe dafür geben, im Einzelfall eine Verletzung der dritten Normalform in Kauf zu nehmen, aber diese Gründe müssen dann aber auch stichhaltig sein. Man wird es als schweren "Kunstfehler" ansehen, wenn die dritte Normalform aus schlichter Unkenntnis nicht erreicht wurde.
4.3 Weitere Normalformen
Die vierte und fünfte Normalform sind wohl deswegen nicht so populär, weil die Situationen unwahrscheinlicher sind, in denen eine Verletzung der Normalformenbedingungen zu erwarten ist. Dies vor allen Dingen deshalb, weil man bereits intuitiv solche Verletzungen vermeidet. Insbesondere wenn man den Weg wählt, zunächst ein ER-Modell aufzustellen (wie es im nächsten Abschnitt beschrieben wird), das dann in einen relationalen Entwurf umgesetzt wird, reicht die Prüfung auf dritte Normalform. Verletzungen der zweiten oder dritten Normalform sind zwar nicht zu erwarten, aber immerhin denkbar und sollten durch Nachprüfen ausgeschlossen werden. In allen praktisch relevanten Fällen kann davon ausgegangen werden, daß dann auch die Bedingungen der vierten und fünften Normalform nicht verletzt sind.
4.4 Integritätsbedingungen
Die Forderung nach Integrität einer Datenbank zielt darauf, daß das gespeicherte Datenabbild tatsächlich auch der Wirklichkeit entsprechen muß. Fehlerhafte Eingaben, unterlassene Pflege (Updates) stellen schnell den Nutzen einer Datenbank in Frage. Datenintegrität läßt sich beim Datenbankentwurf nicht erzwingen, jedoch in speziellen wichtigen Fällen unterstützen.
- Datentypen und Wertebereiche sind auf der Ebene einzelner Attribute
ein wichtiges Instrument, um Datenfehler zu entdecken und auszuschließen.
- Eine weitere Klasse möglicher Fehler wird durch strukturelle Eigenschaften der Datenbank in Verbindung mit der Überprüfung von Schlüsseleigenschaft und von Fremdschlüsseln (Referenzielle Integrität; siehe Def. 8) sichergestellt.
Wollte man versehentlich einem Kurs einen zweiten Bereich zuordnen, so müßte man zwei Datensätze mit gleichem Schlüsselwert eintragen. Wollte man einen Bereich X zuordnen, den es gar nicht gibt, so tritt X als Schlüsselwert in BEREICH gar nicht auf.
- Zusätzliche Bedingungen können formalsprachlich (Aussagenlogik, Prädikatenlogik, Programmiersprachen-Notation) oder natürlichsprachig als eigener Teil des Datenmodells definiert werden.
Beispielsweise könnte für Kurse aus dem Bereich Technik eine Teil-nehmer-beschrän-kung auf 16 Personen gelten. Mehr als 16 Teilnehmer dürfen dann nicht in der Datenbank eingetragen sein.
5. Entity Relationship Modell
- Entstehung und Stellenwert
- Basis-Elemente des ERM
- Erweiterungen des elementaren ERM
- Notationsvarianten
- Diskussion der Modellierungsreichhaltigkeit
5.1 Entstehung und Stellenwert
Das Entity Relationship Modell benennt im Grunde eine Klasse von Ansätzen zur Datenmodellierung, die auf einem Vorschlag von Chen basieren und von denen es viele Varianten gibt, die sich in Notation und Ausdruckskraft unterscheiden. Chen hatte - erfolgreich - versucht, eine Entwurfsmethode vorzuschlagen, die unabhängig vom verwendeten Datenmodell (relational, hierarchisch, netzwerk) ist. Er ging davon aus, daß es für den Menschen natürlich ist, die Welt als etwas wahrzunehmen, in der Dinge (Objekte, Entitäten, "Entities") existieren, zwischen denen gegebenenfalls Beziehungen ("Relationships") bestehen. Ein Datenbankschema für eine solche Welt muß also die Klassen relevanter Entitäten sowie die Klassen relevanter Beziehungstypen umfassen. Es steht demnach nicht ein formaler Begriff wie der der funktionalen Abhängigkeit" im Zentrum der Betrachtung, sondern die Art und Weise, wie der Anwender die Welt sieht und interpretiert. Es geht darum festzustellen, welches die Objekte und welches die Beziehungen sind, die dieser Anwender wahrnimmt. Es handelt sich also um einen Ansatz, der von der Bedeutung der Welt für den Anwender ausgeht, um einen semantischen Ansatz der Datenmodellierung.
Es hat sich für die Verbreitung der ER-Methode sicher sehr günstig erwiesen, daß der zentralen Rolle des Anwenders und seiner Weltsicht eine Form der Darstellung entspricht, die sich für eine Kommunikation besonders gut eignet: die der graphischen Darstellung. Ein ER-Modell hat demnach drei Aufgaben zu erfüllen:- Es ist das Medium, in der der Datenbankentwickler seine Überlegungen
formuliert und entwickelt.
- Es dient als Medium zur Verständigung zwischen Entwickler
und Anwender, insbesondere zu Verifizierung des Datenbankentwurfs.
- Es ist der Ausgangspunkt für die Festlegung des Datenbankschemas, also --- im Falle einer relationalen Datenbank --- für die Festlegung der einzelnen Tabellen.
5.2 Basis-Elemente des ERM
Abbildung 4.6 zeigt einen Auschnitt aus unserer Beispielwelt (Abschn. 4.3) und soll zur Einführung und Erläuterung dienen. Wir bedienen uns dabei einer Notation wie sie in verwendet wird und die nach Meinung des Verfassers einen besonders guten Kompromiß zwischen Einfachheit in der Darstellung und Präzision der Modellierung darstellt.
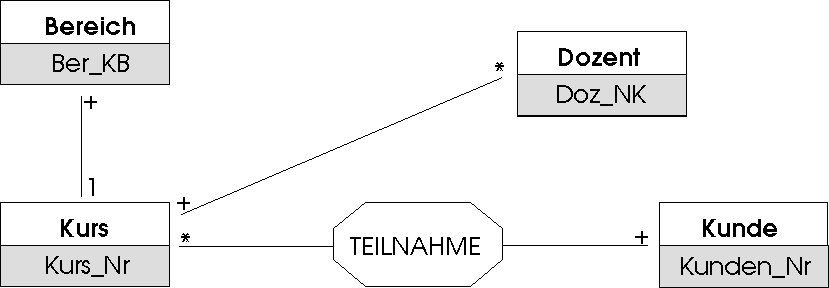
Abbildung 4.6: Ein erstes ER-Modell: Ein Ausschnitt aus der Welt des Hildeshofer Weiterbildungszentrums.Objektklassen
Frau Sabine Sandmann-Süllenberger oder Herr Winfried Meiher sind im Sinne des Entity Relationship Modells Objekte (Entitäten, Entities) der darzustellenden Welt, genauso wie die Kurse Nr. 153 ("Englisch auf Reisen") oder 142 ("DOS-Einführung"). Sie sind Instanzen (Exemplare) der Objektklassen KUNDE und KURS, denen in der beruflichen Welt von Frau Katrin Kleitz vom Hildeshofer Zentrum eine große Bedeutung zukommt. Semantische Datenmodellierung beschäftigt sich also zunächst damit, die relevanten Objekte einer Miniwelt zu identifizieren und anschließend zu Objektklassen zu generalisieren. Diese Objektklassen sind ein erstes Teilergebnis für die konzeptionelle Datenmodellierung, die Objekte selbst werden später in der Datenbank repräsentiert. In Abb. 4.6 erkennen wir, wie Objektklassen im ERM dargestellt werden: als Rechtecke mit der Objektklassenbenennung und in der Regel mit einem (im Ausnahmefall können es auch mehrere sein) Attribut mit identifizierender Eigenschaft (Schlüsselattribut, siehe Def. 3). Die Objektklassen benötigen darüber hinaus eine detailliertere Beschreibung durch Attribute: Die Objektklasse KUNDE wird über das Schlüsselattribut Kunden_Nr hinaus beschrieben durch Attribute für den Vornamen, den Nachnamen und --- weil in der Teilnehmerbestätigung bei der Anrede differenziert werden muß --- das Geschlecht. Weiter Attribute zu Kunde erübrigen sich, da eine eigene Adressdatenbank über die Kundennummer angeschlossen werden soll (Vorgabe in Abschn. 4.3). Das Gesamtergebnis der Detailbeschreibung sehen wir in Abb. 4.7 als Ergänzung zu Abb. 4.6.

Abbildung 4.7: Objektklassen mit Attributen. Ergänzung zu Abb. 4.6. Datentypen in Anlehnung an SQL, die genormte Definitions- und Abfragesprache für RDBMSBeim Vergleich mit den Relationen, die der Normalisierungsprozess geliefert hat (Abb. 4.5) fällt auf, daß in Abb. 4.7 der Fremdschlüssel BER_KB nicht zur Beschreibung des Objektklasse KURS gehört. Beim Relationenmodell dient dieser Fremdschlüssel der Verbindung der Tabellen KURS und BEREICH. Beim ERM treten Fremdschlüssel grundsätzlich niemals auf, denn die Beziehungen (Verbindungen) zwischen Objektklassen werden anders und viel deutlicher modelliert als im Relationenmodell.
Beziehungstypen
In der Welt des Hildesheimer Zentrums gibt es nicht nur Objekte, sondern auch Beziehungen zwischen Objekten (Relationships): Frau Sabine Sandmann-Süllenberger nimmt am Kurs Nr. 153 ("Englisch auf Reisen") teil, die Dozenten W. Kühnel und A. Morx halten den Kurs Nr. 104 ("Business English II"). Analog zur bisherigen Vorgehensweise können auch diese Beziehungen zu Beziehungstypen generalisiert werden: TEILNAHME ist dann beispielsweise ein Beziehungstyp, der KUNDE und KURS verbindet. Wir werden zunächst zwei verschiedene Arten von Beziehungstypen unterscheiden:
Informationstragende Beziehungstypen, denen eigene Attribute zugeordnet werden müssen. Sie durch ein eigenes Symbol dargestellt (Abb. 4.6, Beispiel TEILNAHME), benannt und bekommen eine Beschreibung analog zu der der Objektklassen (Abb. 4.8)
Einfache Beziehungstypen, die durch eine schlichte Verbindungslinie zwischen den Objektklassen dargestellt werden (Beispiele in Abb. 4.6: KURS -- BEREICH, KURS -- DOZENT).

Abbildung 4.8: Informationstragende Beziehung. Ergänzung zu Abb. 4.7Es dürfte unmittelbar einleuchten, warum im ER-Modell die Verwendung von Fremdschlüsseln bei Objektklassen zu den "Todsünden" gehört: Entweder sind Fremdschlüssel redundant zur Darstellung der Beziehungstypen und damit überflüssig. Oder aber --- viel schlimmer --- sie werden alternativ verwendet. In diesem Fall sagt das ER-Modell fälschlicherweise, daß zwischen zwei Objektklassen keine Beziehung besteht, wobei erst das Studium der Attributlisten aufdeckt, daß doch eine Beziehung existiert: versteckt realisiert durch einen Fremdschlüssel!
Spezielle Konstellationen. Anfänger scheuen sich in der Regel, Beziehungstypen in Betracht zu ziehen, die eine Objektklasse mit sich selbst verbinden. Tatsächlich gibt es aber Gegebenheiten, die genau so modelliert werden müssen. Ein Beziehungstyp, der beispielsweise KURS mit KURS verbindet, definiert keineswegs die Beziehung eines Kurses mit sich selbst, sondern eine Beziehung zwischen zwei Objekten, die eben beide vom Typ KURS sind. Das könnte eine Beziehung sein, die den Besuch gewisser Kurse zur Voraussetzung des Besuchs anderer Kurse macht. Andere gleichartige Standardfälle sind Stücklisten (Bauteile bestehen aus anderen Bauteilen) oder andere Hierarchien (ein Deskriptor ist Oberbegriff anderer Deskriptoren).
Ein weiterer Spezialfall sind Beziehungen, an denen mehr als zwei Objektklassen beteiligt sind. Damit gehen unterschiedliche ERM-Varianten unterschiedlich um. Unsere Lösung für diesen Fall wird in Abschnitt 4.5.3 behandelt.
Kardinalitätsangaben. Einfache und informationstragende Beziehungen werden in einem wichtigen Aspekt noch genauer kategorisiert: Es geht um die Anzahl der Objekte, in Beziehung gesetzt werden können. Ältere und schlichtere Notationen verwenden eine Typisierung mit 4 Fällen: Ein Beziehungstyp zwischen O1 und O2 ist vom Typ
1:1, wenn jedem Exemplar von O1 maximal eine Instanz von O2 zugeordnet werden kann und umgekehrt (eins-zu-eins-Beziehung).
1:n, wenn jedem Exemplar von O1 viele Instanzen von O2 zugeordnet werden können, aber jedem O2 nur maximal ein O1 (eins-zu-viele-Beziehung).
Der Beziehungstyp BEREICH--KURS ist vom Typ 1:n, denn zu je einem Bereich gehören viele Kurse, aber jeder Kurs gehört in genau nur einen Bereich.
n:1, wenn... --- dieser Fall entspricht 1:n, nur mit vertauschten Rollen hinsichtlich O1 und O2
n:m, wenn jedem Exemplar von O1viele Instanzen von O2zugeordnet werden können und umgekehrt (viele-zu-viele-Beziehung).
Der Beziehungstyp DOZENT--KURS ist vom Typ n:m, denn ein Dozent kann viele Kurse halten und ein Kurs kann von mehr als einem Dozenten gehalten werden.
Die Verwendung dieser Notation wird in Abschnitt 4.5.4 illustriert --- in Abb. 4.6 wird dagegen differenzierter gearbeitet. Das Prinzip ist einfach: Wir stellen uns vor, daß wir für den betrachteten Beziehungstyp eine Tabelle einrichten und fragen danach, wie häufig Werte der beteiligten Fremdschlüssel in dieser Tabelle vorkommen können:
n: Ein Fremdschlüsselwert muß genau n mal in der Tabelle vorkommen. Den häufigsten Fall gibt n=1 ab
[min,max]: Ein Fremdschlüsselwert muß mindestens min mal und darf höchstens max mal in der Tabelle vorkommen. Den häufigsten Fall liefert min=0, max=1.
* ist eine auch in vielen anderen Fällen gebräuchliche Abkürzung für [0,unendlich]. Ein Fremdschlüsselwert muß überhaupt nicht, darf aber beliebig oft auftreten.
+ ist eine auch in vielen anderen Fällen gebräuchliche Abkürzung für [1,unendlich]. Ein Fremdschlüsselwert muß mindestens einmal und darf beliebig oft auftreten.
Betrachten wir den Fall der TEILNAHME in Abb. 4.6. Die Beziehungstabelle enthält die Fremdschlüssel Kunden_Nr und Kurs-Nr (siehe Abb. 4.9). Eine Kundennummer kommt so oft in dieser Tabelle vor, wie es Kurse gibt, die dieser Kunde besucht (oder besucht hat). Weil ein Kunde erst dann eingetragen wird, wenn er als Kunde in Erscheinung tritt, demnach also mindestens einen Kurs besucht, muß jede Kundennummer mindestens einmal vorkommen: Deshalb die Einordnung +. Andererseits kommt jede Kursnummer in der Beziehungstabelle so oft vor, wie sich Kunden für den Kurs angemeldet haben. Zum Zeitpunkt des Prospektdrucks werden dies gar keine Kunden sein: Deshalb die Einordnung *.
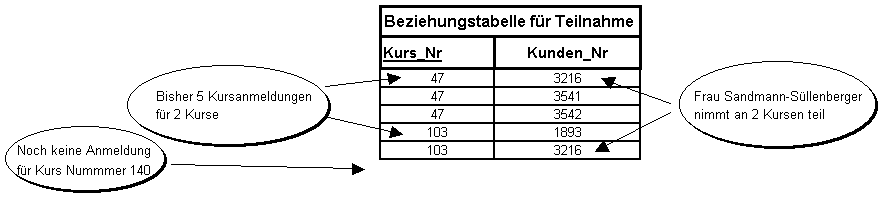
Abbildung 4.9: Kardinalitätsüberprüfung in der Beziehungstabelle: Beispiel TEILNAHME
Abbildung 4.10: Attribute der Objektklasse URTEIL_TEXT, die in Abb. 4.11 Verwendung findet.In gleicher Weise bestimmen sich die übrigen Kardinalitätsangaben der anderen Beziehungstypen in Abb. 4.6. Der Stellenwert der Spezifikation von Beziehungstypen ergibt sich aus zwei Überlegungen:
- Die Kardinalitätsangaben stellen Integritätsbedingungen
dar: Das Modell sagt beispielsweise, daß es keinen Kurs
ohne eine Bereichszuordnung geben darf; Ein Kurs ohne Bereich
wäre also als Fehler in der Datenbank zu werten.
- Von der Art der Beziehungstypen wird es entscheidend abhängen, wie diese in der Datenbank realisiert werden müssen.
5.3 Erweiterungen des elementaren ERM
Beziehungsobjekte: Beziehungen zu Beziehungen
Das ER-Modell aus Abb. 4.6 deckt nicht das gesamte Anwendungsbeispiel aus Abschnitt 4.3 ab: Es enthält nicht die Textbausteine, die man einfach als Objektklasse URTEIL_TEXT modellieren kann und sagt nicht, wie diese Objektklasse an das Vorhandene angebunden werden soll. Letzeres ist das Problem.
Die Textbausteine können nicht zu KUNDE in Beziehung gesetzt werden, da ein Kunde mehrere Kurse besuchen kann und nicht klar wäre, für welchen Kurs er seine Beurteilung bekommt. Mit der gleichen Argumentation verbietet sich auch die Anbindung an KURS, denn ein Kurs hat viele Teilnehmer, die keinesfalls alle die gleiche Beurteilung bekommen müssen. Als Attribut der informationstragenden Beziehung TEILNAHME sind sowohl Textb_Nr als auch Textbaustein ungeeignet:
Textbaustein ist zweifellos nicht ein Attribut von TEILNAHME, sondern ein Atribut von URTEIL_TEXT.
Textb_Nr ist ein Fremdschlüssel und darf keinesfalls als "heimlicher" Beziehungsstifter mißbraucht werden.
Einen Ausweg hat man gefunden, wenn man TEILNAHME zu einer Objektklasse umdeutet, die über Beziehungstypen mit KUNDE, KURS und URTEIL_TEXT verbunden wird. Eleganter und unter Modellierungsgesichtspunkten präziser ist die Lösung, die in Abb. 4.11 unter Verwendung eines neuen Konstrukts gewählt wird: TEILNAHME bleibt im Kern ein informationstragender Beziehungstyp zwischen KUNDE und KURS. Er tritt aber gegenüber URTEIL_TEXT selbst in der Rolle einer Objektklasse auf, die mittels eines einfachen Beziehungstyps an URTEIL_TEXT angebunden wird. Wir nennen TEILNAHME in Abb. 4.11 ein Beziehungsobjekt. Machen wir uns klar, was Beziehungsobjekte als Modellierungsoption leisten: Sie gestatten die differenzierte Modellierung von Beziehungstypen, an denen mehr als zwei Objektklassen beteiligt sind!
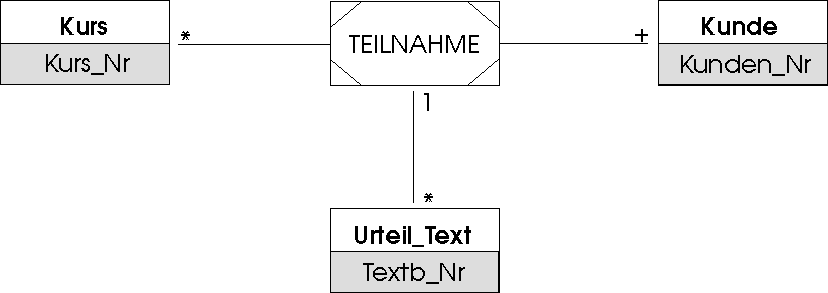
Abbildung 4.11: Beziehungsobjekte modellieren Beziehungen zwischen mehr als 2 Objektklassen. Hier ein ergänzter Ausschnitt aus Abb. 4.6Abstraktionsbeziehung
Mit der Ergänzung durch die Abbildungen 4.11 und 4.10 ist unser ER-Modell, dokumentiert durch die Abbildungen 4.6 und 4.7 komplett. Es soll abschließend jedoch eine Modellierungsvariante diskutiert werden, die von einer wichtigen speziellen Beziehung zwischen Objektklassen Gebrauch macht: der Abstraktionsbeziehung.
Angenommen, die neue Dozentin Tina Wolf beschließt, zur Eingewöhnung und eigenen Weiterbildung selbst an einigen Kursen teilzunehmen. Das hat zur Folge, daß sie zweimal mit Name und Vorname in der Datenbank gespeichert werden wird: als Instanz von DOZENT und von KUNDE. Es ist durchaus denkbar, daß bei Unachtsamkeit ein Namenswechsel etwa das produziert, was anhand von Abb. 4.1 als Änderungs-Anomalie besprochen wurde: Die neue Dozentin it mit zwei verschiedenen Nachnamen in derselben Datenbank repräsentiert. Die Datenbank ist inkonsistent!
Der geschilderte Fall dürfte beim Hildeshofer Zentrum von geringer praktischer Relevanz sein. Objekte vom Typ KUNDE und solche von Typ DOZENT unterscheiden sich deutlich im Hinblick auf die Attribute, durch die sie beschrieben werden müssen, so daß die bisher gewählte Lösung sicher als brauchbar zu beurteilen ist. Dennoch ist es der Überlegung wert, wie man das angesprochene Problem beseitigen kann.
Das Problem verschwindet, wenn wir die Objektklassen KUNDE und DOZENT weitergehend generalisieren und eine neue zusätzliche Objektklasse PERSON einführen. Personen werden zweckmäßigerweise durch einen künstlichen Schlüssel P_Nr identifiziert und besitzen Attributwerte für Vorname und Nachname. Bei den Objektklassen KUNDE und PERSON handelt es sich um Spezialisierungen (Unterbegriffe) von PERSON, die den dort zugeordneten Attributen weitere hinzufügen: KUNDE kann auf die bisherige Kunden_Nr verzichten, da diese äquivalent zum Attribut P_Nr ist, benötigt aber noch Geschlecht. DOZENT benötigt Doz_NK, Doz_Tel und Kompetenzbereich. Mit den Attributen der beteiligten Objektklassen verhält es sich also genau wie mit den Merkmalen von Begriffen: Jeder Unterbegriff erbt alle Merkmale des Oberbegriffs und unterscheidet sich durch mindestens ein weiteres Merkmal. "Vererbung" ist tatsächlich auch der Fachbegriff, mit dem man den Prozess benennt, der das Wissen über den Oberbegriff (hier im Beispiel: die Attribute von PERSON) auf die Unterbegriffe (hier: KUNDE, DOZENT) überträgt. Abb. 4.12 zeigt, wie diese neue Sicht im ER-Modell graphisch dargestellt wird. Abb. 4.13 ergänzt die Attributzuordnungen.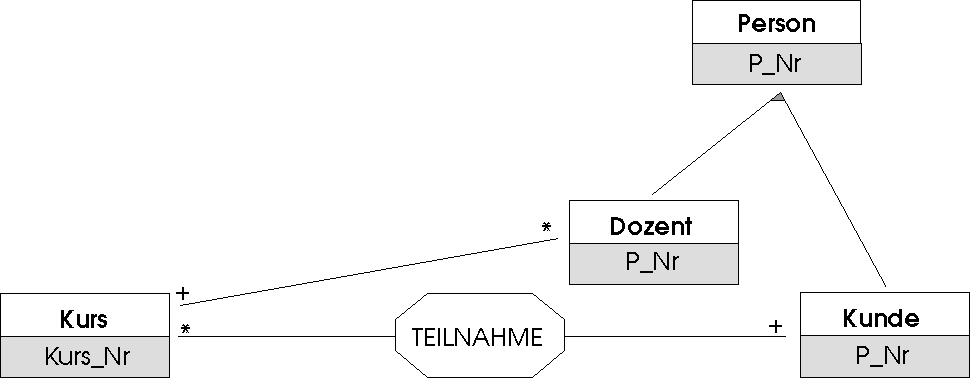
Abbildung 4.12: Abstraktionsbeziehungen im ER-Modell: PERSON als Oberbegriff zu KUNDE und DOZENT
Abbildung 4.13: Attribute von Ober- und Unterbegriffen. Die Vererbung sorgt dafür, daß die Attribute von PERSON implizit auch den Unterbegriffen zugeschlagen werden. Ergänzung zu Abb. 4.125.4 Notationsvarianten
Es ist undenkbar, die vielen Varanten aufzählen zu wollen, in denen das ERM vorkommt und in denen es graphisch dargestellt wird. Es soll genügen, die unmittelbar auf citeChen76 zurückgehende Notation der bisher verwendeten gegenüberzustellen (Abb. 4.14) sowie die gebräuchlichsten Notationen für Beziehungstypen aufzulisten (Abb. 4.15).

Abbildung 4.14: Das Hildeshofer ER-Modell (Notation basierend auf Chen76)Auf eine Mehrdeutigkeit muß hingewiesen werden: Wird das einfache Notationsschema 1:1, 1:n, n:1, n:m gewählt, so ist stets die Null eingeschlossen. Wird dagegen die Notation um das "c" (für conditional) erweitert, dann schließt etwa 1:n die Null aus, denn für den Einschluß der Null existiert dann ja eine separate Notation.
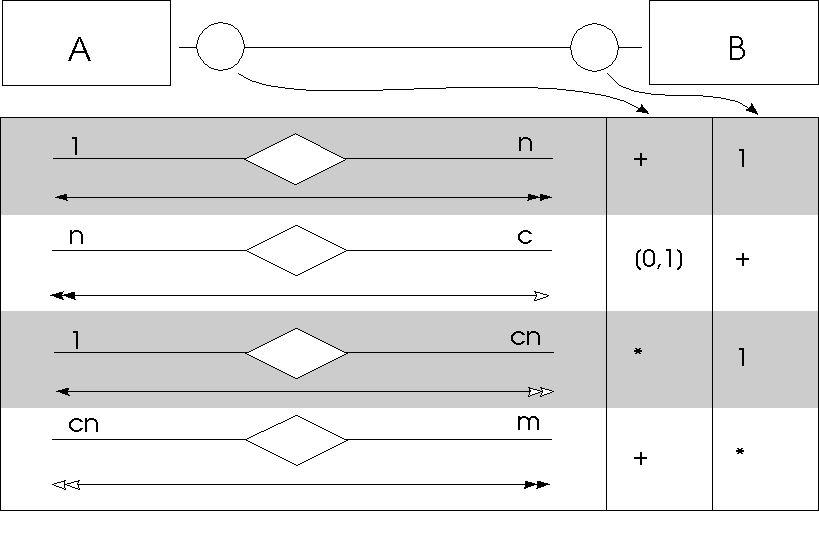
Abbildung 4.15: Alternative Konventionen zur Darstellung von Beziehungstypen. Beschränkt auf ausgewählte Fälle, deren systematische Verallgemeinerung der LeserIn überlassen wird.
5.5 Diskussion der Modellierungsreichhaltigkeit
Abschließend soll systematisch zusammengefaßt werden, welche der grundlegenden Datenabstraktionen das ERM anbietet: Aggregation, die Zusammenfassung von kleineren zu neuen Einheiten findet sich beim ER-Modell bei-
Zusammenfassung von Attributen zu Objektklassen.
-
Zusammenfassung von Objektklassen bzw. Beziehungsobjekten zu Beziehungstypen.
-
der Bildung "schwacher Objekttypen" bzw. erweiterten Objekten , die hier allerdings nicht behandelt wurden.
Generalisierung, also die Bildung von Taxonomien wird durch die Abstraktionsrelation realisiert wird der untergeordnete Begriff als "Subobjekt" bezeichnet).
Association, bei der neue Einheiten als underlineMenge bereits bekannter Einheiten entstehen, wird im ERM nicht unterstützt. So gibt es keinen Konstruktionsmechanismus, der Personen zu Übungsgruppen mit eigenen Attributen zusammenfaßt.
Klassifikation, also die Zuordnung einer Instanz zu einer Klasse ist im ER-Modell implizit als Unterscheidung zwischen Schema und Wert vorhanden. Weil das ER-Modell der Schema-Definition dient, kommen die Instanzen (Werte) im ER-Modell selbst nicht vor. Eine solch strikte Trennung zwischen Schema und Werten ist nicht überall gegeben. Mittels KL-ONE beispielsweise, einer aus den KI-Bereich kommenden Modellierungssprache (citeBra85), lassen sich Unterbegriffe nicht nur durch zusätzliche Attribute definieren, sondern auch durch Einschränkungen hinsichtlich Wertebereich und Wert. Etwa folgender Art: TECHNIKKURS ist eine Spezialisierung von KURS, wobei der Bereich, aus dem der KURS stammt auf den Wert "Technik" (Kennbuchstabe "T") eingeschränkt ist.
6. Umsetzung eines ER-Modells in einen relationalen Datenbankentwurf
Die primäre Nutzung des ERM dürfte gegenwärtig die Vorbereitung eines relationalen Datenbankentwurfs sein: Systematisch werden die Konstrukte des ER-Modells, die Objekte, Beziehungen und Beziehungsobjekte in Tabellen (Relationen) umgesetzt und --- sozusagen als Endkontrolle - hinsichtlich dritter Normalform überprüft.
Die Umsetzung beginnt mit den Objektklassen, die praktisch schon als Relationen vorliegen: es fehlt eigentlich nur all dies, was mit Fremdschlüsseln zu tun hat und was im ERM mittels Beziehungstypen modelliert wird.
Die Strategie zur Umsetzung der Beziehungstypen ist einfach:Viele-zu-viele-Beziehungen erfordern stets eine eigene Relation. Deren Schlüssel ist ein Kombinationsschlüssel, bestehend mindestens aus den Fremdschlüsseln der beteiligten Relationen. Beispiel: TEILNAHME Alle übrigen Fälle von Beziehungen kommen ohne separate Tabelle aus: Wenn einer Objektklasse O1 maximal ein Objekt der Objektklasse O2 zugeordnet werde kann, dann wird die Relation für O1 um ein Attribut mit dem Fremdschlüssel aus O2 erweitert. beispiel Beispiel: KURS--DOZENT, KURS--BEREICH, TEILNAHME--URTEIL_TEXT Handelt es sich um eine informationstragende Beziehung, dann werden die Attribute der Beziehung dort untergebracht, wo auch die Beziehung selbst realisiert ist: in der Objekt-Relation oder aber in einer eigenen Beziehungstabelle. An dieser Stelle können wir präziser als in Abschnitt 4.3 klarmachen, daß man mit der Verletzung der 4. Normalform nicht rechnen muß: Die 4. Normalform fordert nämlich, daß man nicht zwei n:m-Beziehungen in einer einzigen Tabelle realisieren darf: Ein Fehler also, der auf dem Weg über ein ERM als völlig ausgeschlossen gelten kann. Das Ergebnis des relationalen Datenbankentwurfs, der systematisch aus unserem ER-Modell folgt, ist uns bereits bekannt: Es ist hier identisch mit der Menge von Relationen, die wir durch den Normalisierungsprozess erhalten haben .
7. Modellierung von Operationen und Funktionen
Datenbanken unterstützen in erster Linie datenintensive Anwendungen. Dies bedeutet, daß in aller Regel das Datenmodell um eine Funktionsmodellierung zu ergänzen ist, die hier nicht Gegenstand des Beitrags war.
Die Schnittstelle zwischen Daten- und Funktionsmodellierung muß immer als Quelle möglicher Fehler und Inkompatibilitäten angesehen werden. Der zunehmend populär werdende objektorientierte Ansatz setzt genau an dieser Schwachstelle an und erweitert die Aufgabe der Datenmodellierung: Objekte werden danach nicht nur durch Daten repräsentiert, sondern sie haben auch ein Verhalten, das mit Gegenstand der Modellierung sein muß.
In gewissem Sinn führen objektorientierte Datenbanken den Gedanken nur konsequent fort, mit dem sich die Datenbanken "erster Generation" auf den Weg gemacht haben. Diese haben Definition und Verwaltung der Daten aus den Anwendungsprogrammen herausgezogen und zentralisiert. So läßt sich Konsistenz des Datenbestandes zuverlässig erreichen, und der Aufwand für Pflege und Weiterentwicklung bleibt kalkulierbar. Dieselben Argumente lassen sich nun aber auf die Funktionen anwenden, die in den vielen Anwendungsprogrammen stecken und die die Daten abfragen und manipulieren. Ein und dieselbe Funktion kann --- ohne daß dies systematisch erfaßt ist --- beliebig oft realisiert sein und vielleicht nicht in allen Fällen fehlerfrei! Wenn man dagegen die Funktionen in gleicher Weise wie die Daten in der Datenbank verwaltet, läßt sich auch hier ein wertvoller Gewinn an Sicherheit, Konsistenz und Wirtschaftlichkeit erreichen.
Ein konzeptioneller Datenbankentwurf (wie in diesem Beitrag behandelt) wird dabei nicht obsolet, sondern erweitert. Eine tragende Rolle übernimmt die Abstraktionsrelation, die die Vielzahl der definierten Objekte in handhabbaren Hierarchien organisiert. Das Vererbungsprinzip bezieht sich dabei nicht nur auf Attribute, sondern gleichermaßen auf Funktionen: Wenn OBJEKT etwas ist das man ausdrucken kann und PERSON ist ein Unterbegriff von OBJEKT, dann kann man auch PERSON ausdrucken. PERSON erbt also die Funktion ausdrucken.
Einen großen Gewinn an Sicherheit bringt das Prinzip der Kapselung, das den Datenbanken bereits bisher im Hinblick auf Daten Datenunabhängigkeit beschert hat: Weil kein Anwendungsprogramm weiß, wie die Daten gespeichert sind, kann dieses Wissen nach einer Änderung der Datenstruktur auch nicht falsch geworden sein und Fehler verursachen. Unwissenheit schützt also vor Fehlern! Dasselbe Prinzip gilt nun auch auf der Ebene von Funktionen: Anders als über die einem Objekt bekannten Funktionen kann man nicht mit diesem Objekt in Kontakt kommen. Über die Realisierung dieser Funktionen wird nach außen nichts bekannt. Sofern also die Funktionen richtig modelliert und realisiert sind (und dies nur genau ein Mal, nämlich bei der Definition der entsprechenden Objektklasse), sind Fehler an dieser Stelle ausgeschlossen.Wer also die Aufgabe eines objektorientierten Datenbankentwurfs auf sich zukommen sieht, der hat mit seiner Beschäftigung mit dem ERM einen sinnvollen ersten Schritt getan.
Literatur :
Brachman, R.J.; Schmolze, J.G.: An Overview of the KL-ONE Knowledge Representation System. Cognitive Science 9(1985): S. 171-216.
Chen, P.-S.: The Entity-Relationship Model --- Towards an Unified View of Data. ACM Transaction on Data Base Systems, 1(1976)1: 9-36.
Date, C.J.: An Introduction to Database Systems. Vol.I, 5. Aufl., Reading, Mass,: Addison-Wesley, 1990.
Denert, X: Software Engineering. Berlin, Heidelberg et al.: Springer, 1991.
Meier, A.: Relationale Datenbanken. Heidelberg et al.: Springer, 1992.
Schlageter, G.; Stucky, W.: Datenbanksysteme --- Konzepte und Modelle. 3. Aufl., Stuttgart, 1993
Vetter, M.: Aufbau betrieblicher Informationssysteme mittels objektorientierter, konzeptioneller Datenmodellierung. Stuttgart: Teubner, 1993.
Vossen, G.: Datenmodelle, Datenbanksprachen und Datenbank-Management Systeme. 2. Aufl.,Bonn 1994.
Zehnder, C. A.: Informationssysteme und Datenbanken. Stuttgart: Teubner, 1999.
- In der abzubildenden Welt lassen sich einzelne Datenelemente
mit festumrissener Interpretation abgrenzen. Wenn prinzipiell
die Organisation der benötigten Daten in einer Tabellenform
sinnvoll erscheint, ist diese Voraussetzung erfüllt.
-
Haftungsausschluss:
Haftung für Inhalte
Die Inhalte unserer Seiten wurden mit größter Sorgfalt erstellt. Für die Richtigkeit, Vollständigkeit und Aktualität der Inhalte können wir jedoch keine Gewähr übernehmen. Als Diensteanbieter sind wir gemäß § 7 Abs.1 TMG für eigene Inhalte auf diesen Seiten nach den allgemeinen Gesetzen verantwortlich. Nach §§ 8 bis 10 TMG sind wir als Diensteanbieter jedoch nicht verpflichtet, übermittelte oder gespeicherte fremde Informationen zu überwachen oder nach Umständen zu forschen, die auf eine rechtswidrige Tätigkeit hinweisen. Verpflichtungen zur Entfernung oder Sperrung der Nutzung von Informationen nach den allgemeinen Gesetzen bleiben hiervon unberührt. Eine diesbezügliche Haftung ist jedoch erst ab dem Zeitpunkt der Kenntnis einer konkreten Rechtsverletzung möglich. Bei Bekanntwerden von entsprechenden Rechtsverletzungen werden wir diese Inhalte umgehend entfernen.
Haftung für Links
Unser Angebot enthält Links zu externen Webseiten Dritter, auf deren Inhalte wir keinen Einfluss haben. Deshalb können wir für diese fremden Inhalte auch keine Gewähr übernehmen. Für die Inhalte der verlinkten Seiten ist stets der jeweilige Anbieter oder Betreiber der Seiten verantwortlich. Die verlinkten Seiten wurden zum Zeitpunkt der Verlinkung auf mögliche Rechtsverstöße überprüft. Rechtswidrige Inhalte waren zum Zeitpunkt der Verlinkung nicht erkennbar. Eine permanente inhaltliche Kontrolle der verlinkten Seiten ist jedoch ohne konkrete Anhaltspunkte einer Rechtsverletzung nicht zumutbar. Bei Bekanntwerden von Rechtsverletzungen werden wir derartige Links umgehend entfernen.
Urheberrecht
Die durch die Seitenbetreiber erstellten Inhalte und Werke auf diesen Seiten unterliegen dem deutschen Urheberrecht. Die Vervielfältigung, Bearbeitung, Verbreitung und jede Art der Verwertung außerhalb der Grenzen des Urheberrechtes bedürfen der schriftlichen Zustimmung des jeweiligen Autors bzw. Erstellers. Downloads und Kopien dieser Seite sind nur für den privaten, nicht kommerziellen Gebrauch gestattet. Soweit die Inhalte auf dieser Seite nicht vom Betreiber erstellt wurden, werden die Urheberrechte Dritter beachtet. Insbesondere werden Inhalte Dritter als solche gekennzeichnet. Sollten Sie trotzdem auf eine Urheberrechtsverletzung aufmerksam werden, bitten wir um einen entsprechenden Hinweis. Bei Bekanntwerden von Rechtsverletzungen werden wir derartige Inhalte umgehend entfernen.
Datenschutz
Die Nutzung unserer Webseite ist in der Regel ohne Angabe personenbezogener Daten möglich. Soweit auf unseren Seiten personenbezogene Daten (beispielsweise Name, Anschrift oder eMail-Adressen) erhoben werden, erfolgt dies, soweit möglich, stets auf freiwilliger Basis. Diese Daten werden ohne Ihre ausdrückliche Zustimmung nicht an Dritte weitergegeben.
Wir weisen darauf hin, dass die Datenübertragung im Internet (z.B. bei der Kommunikation per E-Mail) Sicherheitslücken aufweisen kann. Ein lückenloser Schutz der Daten vor dem Zugriff durch Dritte ist nicht möglich.
Der Nutzung von im Rahmen der Impressumspflicht veröffentlichten Kontaktdaten durch Dritte zur Übersendung von nicht ausdrücklich angeforderter Werbung und Informationsmaterialien wird hiermit ausdrücklich widersprochen. Die Betreiber der Seiten behalten sich ausdrücklich rechtliche Schritte im Falle der unverlangten Zusendung von Werbeinformationen, etwa durch Spam-Mails, vor.Quelle: Disclaimer von eRecht24, dem Portal zum Internetrecht von Rechtsanwalt Sören Siebert.

